Understanding Attention Architectures in Modern LLMs
From MHA to MLA: A clear breakdown of how and why modern large language models changed the way they process context and optimize memory.
Understanding Attention Architectures in Modern LLMs
From MHA to MLA: Why modern LLMs changed the way they “pay attention”
When people say a language model “uses attention,” they usually mean the model can look back at earlier tokens and decide which ones matter for predicting the next token. For example, in the sentence:
“Rana gave Priya a book because she helped him.”
The model needs to connect “she” to Priya and “him” to Rana. Attention is the mechanism that helps the model make those connections.
The original Transformer architecture was built around attention, especially multi-head attention, where several attention heads look at the same text from different perspectives. This idea became the foundation for modern LLMs.
The core idea: Query, Key, Value
A simple way to understand attention is through three objects:
- Query means: “What am I looking for?”
- Key means: “What information does each previous token offer?”
- Value means: "What actual information should I bring forward if this token is useful?"
So when the model reads “she”, the query might ask: “Who is the female person mentioned earlier?” The keys help it find Priya, and the value brings Priya’s information forward.
During inference, the model stores previous Key and Value tensors in memory. This stored memory is called the KV cache. The bigger the context, the bigger the KV cache becomes. This is why attention design matters so much for serving LLMs efficiently.
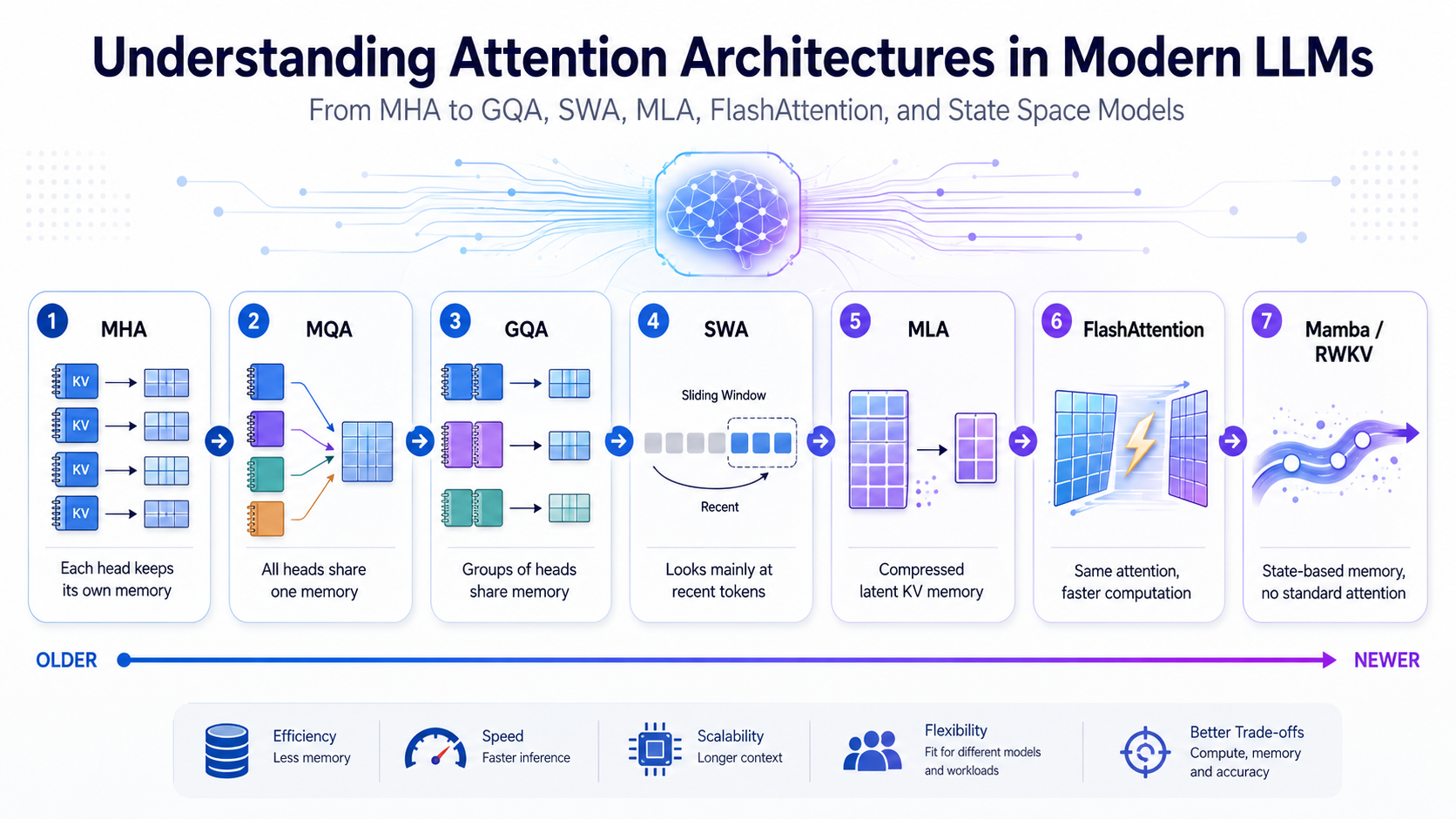
1. MHA: Multi-Head Attention
MHA is the classic attention design. Imagine 32 people reading the same paragraph. Each person focuses on something different:
- One tracks names.
- One tracks grammar.
- One tracks dates.
- One tracks objects.
- One tracks relationships.
Each attention head has its own Query, Key, and Value projections. This gives the model strong expressive power, but it also creates a large memory cost because every head stores its own KV cache.
Simple example
Sentence:
“The dog chased the ball because it was moving.”
One head may connect “it” to ball. Another may focus on dog chased ball. Another may understand the cause: because it was moving.
MHA is powerful, but expensive.
Memory analogy
Every employee has their own full notebook.
That gives rich understanding, but if you have many employees and a very long document, storage becomes expensive.
2. MQA: Multi-Query Attention
MQA was designed to reduce the cost of decoding. Instead of every attention head having separate Keys and Values, all query heads share a single Key/Value set. This greatly reduces KV cache size and memory bandwidth during generation.
Simple example
Imagine 32 people asking different questions, but they all use the same shared notebook.
They can ask:
- “What is the subject?”
- “What is the object?”
- “Who does the pronoun refer to?”
- “What happened before?”
But they all look into one shared memory store.
This saves memory, but it can reduce expressiveness because all heads are forced to reuse the same Key/Value representation.
Memory analogy
Everyone shares one notebook.
Cheap and fast, but maybe not as detailed.
3. GQA: Grouped-Query Attention
GQA is the practical middle ground between MHA and MQA. Instead of every head having its own KV cache, and instead of all heads sharing one KV cache, groups of query heads share Key/Value heads. GQA was proposed as a way to get much of MQA’s inference speed while preserving more quality than pure MQA.
Simple example
Imagine 32 people split into 8 teams.
Each team has its own notebook. People inside the same team share that notebook. Different teams still have different memory.
This is cheaper than 32 notebooks, but richer than only 1 notebook.
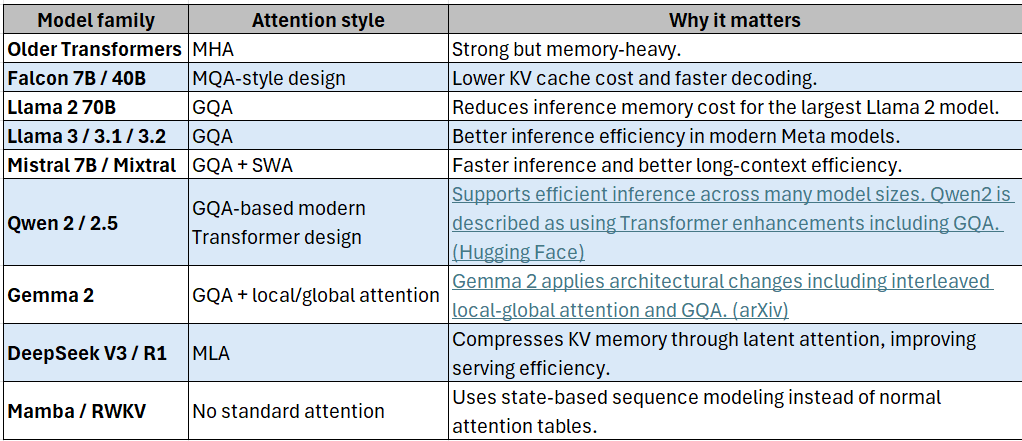
That is why GQA is used in many modern LLMs. Meta said Llama 3 added GQA to the 8B model to help maintain inference efficiency, and Mistral 7B also uses GQA for faster inference.
Memory analogy
Each team shares one notebook.
Good balance: less memory, still good quality
4. SWA: Sliding Window Attention
Sliding Window Attention limits how far back the model actively attends. Instead of looking at the entire conversation every time, the model mostly looks at a recent window of tokens.
This is useful because long-context attention can become expensive. Mistral 7B combines GQA with Sliding Window Attention to handle long sequences with reduced inference cost.
Simple example
Imagine reading a 500-page book, but for each new sentence, you only check the last 10 pages.
That works well when recent context matters most. But if something important happened on page 2, the model may need another mechanism or layer pattern to recover it.
Memory analogy
Only keep the most recent pages open on the desk.
Fast and efficient, but old details may be harder to access directly.
5. MLA: Multi-Head Latent Attention
MLA, used by DeepSeek models, attacks the KV cache problem differently. Instead of storing full Key/Value information for every token, it compresses information into a latent representation. DeepSeek-V2 introduced MLA as part of its efficient inference architecture, and DeepSeek V3/R1 continued this design direction.
Simple example Instead of storing a full paragraph like this:
“Rana gave Priya a book because she helped him with his project.” The model stores a compressed code that captures the important information: Rana → gave book → Priya Priya → helped Rana
Later, the model can use that compressed representation instead of reading a full KV cache.
Memory analogy
Instead of keeping full notebooks, keep compressed notes. This is powerful for long context and high-concurrency serving because KV cache memory is one of the biggest costs during LLM inference.
6. FlashAttention
FlashAttention is not a new attention architecture like MHA, MQA, or GQA. It is a faster and more memory-efficient way to compute attention.
Standard attention can create large intermediate matrices. FlashAttention avoids writing huge attention matrices to slow GPU memory by computing attention in smaller blocks. The original FlashAttention paper describes it as an IO-aware exact attention algorithm that reduces memory reads and writes between GPU memory levels. (arXiv)
Simple example Imagine you need to multiply and compare a huge spreadsheet. Normal attention says:
Create the entire spreadsheet first, then calculate.
FlashAttention says:
Process it block by block, keep only what is needed, and avoid storing unnecessary intermediate data.
Memory analogy
Same attention, smarter calculation. So when you see GQA + FlashAttention, remember:
GQA changes how KV heads are shared. FlashAttention changes how attention is computed efficiently.
7. No Attention: Mamba and RWKV
Some architectures try to avoid standard Transformer attention altogether.
Mamba uses selective state space models and is designed to scale linearly with sequence length instead of using standard attention over all previous tokens. The Mamba paper describes it as an architecture without attention or MLP blocks, designed for efficient long-sequence modeling.
RWKV combines ideas from RNNs and Transformers. It aims to provide Transformer-like parallel training with RNN-like efficient inference.
Simple example
Instead of looking back at every previous word, the model keeps updating a running memory state.
After reading:
“Rana gave Priya a book.” The model updates its internal state: Rana gave something to Priya. When it later sees: “She thanked him.” It uses the running state rather than scanning all previous tokens through attention.
Memory analogy
No notebook lookup. Keep a running summary in your head. This can be very memory-efficient, but it behaves differently from Transformer attention.
How popular model families fit in
The simplest way to remember everything
- MHA: every head has its own memory.
- MQA: all heads share one memory.
- GQA: groups of heads share memory.
- SWA: only look at recent tokens. MLA: store compressed memory.
- FlashAttention: compute attention faster.
- Mamba/RWKV: avoid standard attention and use running state.
The evolution is mostly about one problem:
How can we keep LLM quality high while reducing memory, latency, and serving cost? That is why modern LLMs moved from pure MHA toward GQA, SWA, MLA, FlashAttention, and state-space alternatives.
Final takeaway
Attention is not one fixed thing anymore. The original Transformer used multi-head attention, but production LLMs need to serve long conversations, many users, and large context windows efficiently. That forced the industry to optimize attention.
The trend is clear:
Modern LLM architecture is no longer just about making models bigger. It is about making memory smarter.