Private RAG for Enterprise Documents: Production Architecture in 2026
A senior engineer's guide to building enterprise-grade private RAG systems — covering advanced retrieval pipelines, access-layer design, agentic patterns, evaluation frameworks, and regulatory compliance.
Private RAG for Enterprise Documents: Production Architecture in 2026
Most enterprise RAG implementations fail quietly. Not at demo. Not at launch. They fail three months later, when retrieval returns stale context, answers drift from source material, an employee asks about a restricted policy they shouldn't see, and no one can explain why the system said what it said.
The root cause is almost always the same: the system was designed as a prototype and scaled as one. The ingestion layer is shallow. The retrieval pipeline is a single semantic search call. Access controls are an afterthought. Evaluation is manual and infrequent. Observability is a Grafana panel tracking token count.
This guide is about designing it right the first time — for production, for regulated environments, and for the audit that will eventually come.
Why Basic RAG Falls Short in Enterprise Contexts
A retrieval-augmented generation system has one job: give an LLM the right context so it can produce a grounded, accurate answer. Basic implementations do this with a single embedding similarity search over a flat document index. That works in demos. It fails in production for five compounding reasons:
Vector search alone cannot find what it does not understand semantically. Bi-encoder embeddings compress paragraphs into dense vectors. Precise terminology — contract clause numbers, product codes, regulation identifiers, internal acronyms — is routinely lost in that compression. BM25 keyword search, which the enterprise has used reliably for decades, still outperforms vector search for exact-match queries. Production systems need both.
Chunk boundaries break coherent answers. Fixed-size chunking splits documents at arbitrary token counts. A policy document broken mid-paragraph returns fragments with missing context. The model fills the gap with inference rather than evidence — and hallucination enters through the retrieval layer, not the generation layer. Research from a 2025 clinical decision support study found adaptive chunking hit 87% accuracy versus 13% for fixed-size baselines on the same corpus.
Top-K retrieval returns noise alongside signal. Retrieving twenty chunks and sending all twenty into the model context does not guarantee the most relevant five are in the top positions. Without a reranker, the model's attention is diluted across irrelevant material. Cross-encoder rerankers — scoring each retrieved chunk against the query independently — improve Top-K precision by 15–30% over bi-encoder retrieval alone.
Access control enforced at the application layer is fragile. When permissions are checked after retrieval rather than before, there is a window where unauthorized content enters the pipeline. It may not reach the final answer, but it enters the context. That is a compliance gap.
There is no recovery path when retrieval confidence is low. A basic RAG system either returns an answer or returns nothing. A production system needs thresholds, fallback behaviors, escalation paths, and the ability to flag low-confidence responses before they are served.
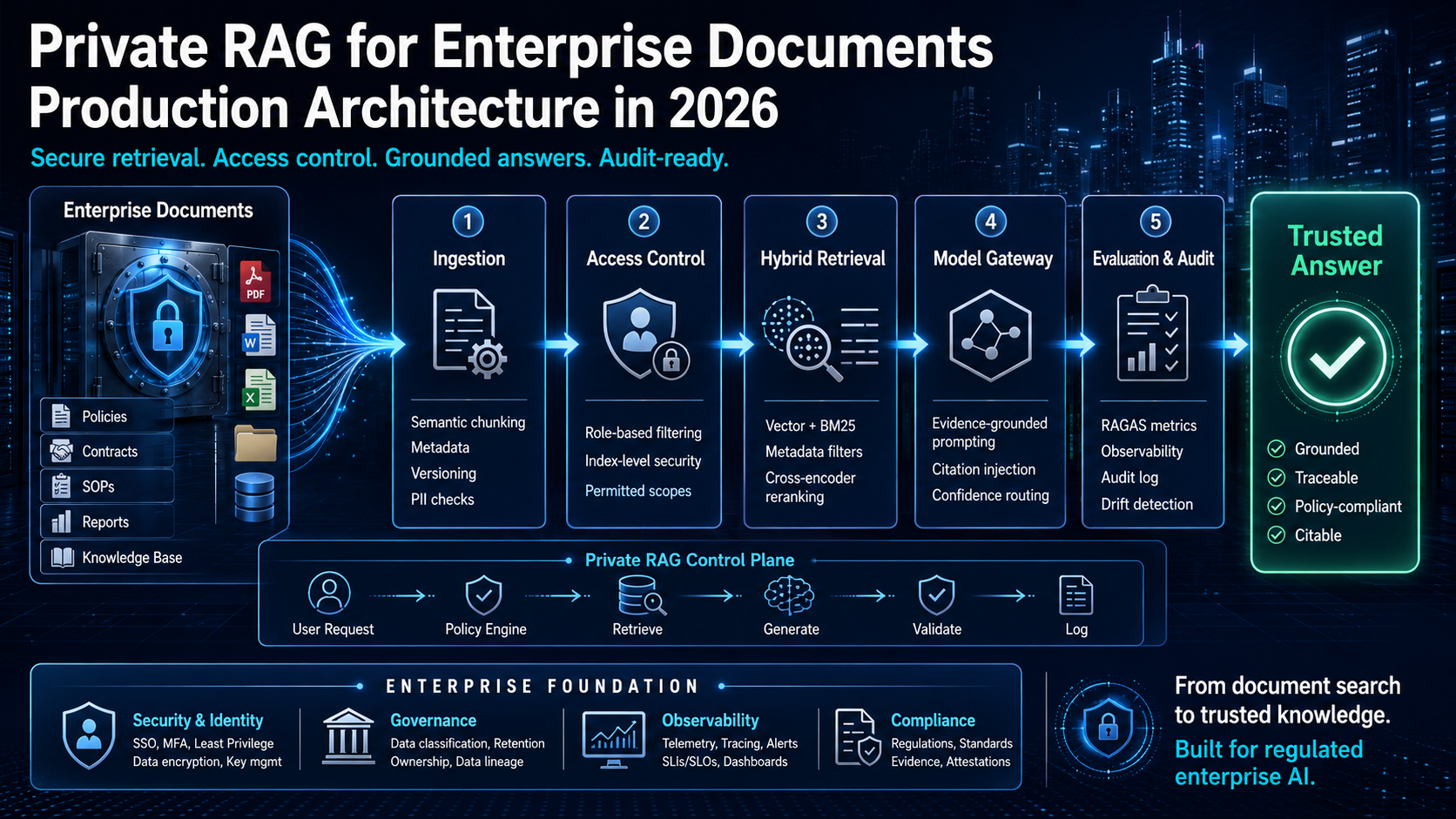
Production Architecture
A production private RAG system is not a single service. It is an integrated pipeline across six functional layers: ingestion, access enforcement, retrieval, generation, evaluation, and observability. Each layer is independently testable, independently replaceable, and independently auditable.
┌─────────────────────────────────────────────────────────────────┐
│ USER INTERFACE (authenticated, role-identified) │
└────────────────────────┬────────────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────────────┐
│ API GATEWAY + POLICY ENGINE │
│ Auth token → identity → role → permitted index scopes │
│ Prompt guardrails → PII detection → input validation │
└────────────────────────┬────────────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────────────┐
│ RETRIEVAL PIPELINE │
│ Query rewriting → Hybrid search (vector + BM25) → │
│ Metadata filtering (access scope, recency, doc type) → │
│ Cross-encoder reranking → Context assembly (≤8K tokens) │
└────────────────────────┬────────────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────────────┐
│ MODEL GATEWAY │
│ Route by sensitivity (cloud / local / air-gapped) → │
│ Evidence-grounded prompt template → Generation → │
│ Hallucination check → Citation injection │
└────────────────────────┬────────────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────────────┐
│ EVALUATION + OBSERVABILITY │
│ RAGAS scoring → Latency + cost tracking → │
│ Audit log (prompt / retrieved docs / answer / user / time) → │
│ Feedback capture → Drift detection │
└─────────────────────────────────────────────────────────────────┘
Layer 1: Intelligent Document Ingestion
The ingestion layer is where most RAG systems accumulate technical debt. Decisions made here constrain every downstream layer. Get them right once; refactoring them later requires full reindexing.
Chunking Strategy by Document Type
There is no universal chunking strategy. The right approach is determined by document structure, downstream query patterns, and retrieval precision requirements.
Semantic chunking splits on paragraph and sentence boundaries rather than fixed token counts, preserving coherent units of meaning. Use this as the default for narrative documents — policies, procedures, meeting notes, and contracts.
Parent-document retrieval indexes small child chunks (128–256 tokens) for precise matching, but returns the parent section (512–1024 tokens) when a child is retrieved. The child's density drives retrieval accuracy; the parent's breadth gives the model sufficient context. This is the most effective pattern for dense technical documentation.
Hierarchical indexing stores documents at multiple granularities simultaneously — full document, section, and paragraph — each as a separate node in the index. Useful when queries range from high-level summarization to clause-level lookup on the same corpus.
Section-aware chunking respects heading structure in PDFs and Word documents, ensuring that a chunk is always a semantically complete unit under a single heading. Required for regulatory documents, SOPs, and standard operating procedures where the heading provides mandatory context.
Metadata as First-Class Infrastructure
Every chunk stored in the vector database must carry a structured metadata envelope. This is not optional. Metadata drives access filtering, citation generation, retention enforcement, and debugging — all simultaneously.
A minimum metadata schema includes:
{
"document_id": "pol-hr-2024-003",
"chunk_id": "pol-hr-2024-003-c007",
"source_path": "s3://company-docs/hr/leave-policy-2024.pdf",
"document_type": "policy",
"department": "HR",
"classification": "internal",
"permitted_roles": ["all-employees"],
"effective_date": "2024-01-01",
"expiry_date": "2025-12-31",
"version": "3.2",
"chunk_index": 7,
"parent_section": "Section 4: Annual Leave Entitlements",
"ingested_at": "2026-06-14T09:00:00Z"
}
Expiry date is particularly important and consistently overlooked. Documents that have passed their effective date should be excluded from retrieval unless the query specifically requests historical context. Serving an answer grounded in a superseded policy is a compliance failure, not a retrieval failure.
Layer 2: Access Control at the Index Level
The most common enterprise RAG security failure is enforcing access controls at the application layer rather than the retrieval layer. If your access control logic runs after retrieval, restricted document content is entering the model context — even if it is filtered from the final response.
Correct access enforcement means the retrieval query itself carries identity-derived scope constraints as hard filters. The vector database never returns chunks whose permitted_roles field does not include the requesting user's role.
def retrieve_with_access_control(
query_embedding: list[float],
user_identity: UserIdentity,
top_k: int = 20
) -> list[Chunk]:
# Derive permitted scopes from identity — never trust client-side claims
permitted_roles = resolve_roles(user_identity.user_id)
permitted_departments = resolve_department_access(user_identity.user_id)
# Access filter is a hard constraint, not a post-retrieval check
access_filter = {
"operator": "AND",
"operands": [
{"path": ["permitted_roles"], "operator": "ContainsAny", "valueTextArray": permitted_roles},
{"path": ["expiry_date"], "operator": "GreaterThan", "valueDate": datetime.utcnow().isoformat()},
{"path": ["classification"], "operator": "In", "valueTextArray": permitted_classifications(user_identity)}
]
}
return vector_db.query(
vector=query_embedding,
filters=access_filter,
limit=top_k,
include_metadata=True
)
For multi-tenant deployments, namespace-level isolation in the vector database provides a stronger boundary than metadata filtering alone. Each tenant operates against a logically separated index partition, eliminating any risk of cross-tenant retrieval regardless of filter correctness.
Layer 3: Advanced Retrieval — Hybrid Search and Reranking
Hybrid Search with Reciprocal Rank Fusion
A single retrieval modality is insufficient for enterprise corpora. Semantic (vector) search finds conceptually relevant documents even when the user's vocabulary differs from the source. Keyword (BM25) search finds exact matches for product codes, policy numbers, regulatory references, and proper nouns that embeddings compress poorly.
Reciprocal Rank Fusion (RRF) merges the ranked results from both modalities without requiring calibrated score normalization:
def reciprocal_rank_fusion(
semantic_results: list[Chunk],
keyword_results: list[Chunk],
k: int = 60
) -> list[Chunk]:
scores: dict[str, float] = {}
doc_map: dict[str, Chunk] = {}
for rank, chunk in enumerate(semantic_results):
scores[chunk.id] = scores.get(chunk.id, 0) + 1 / (k + rank + 1)
doc_map[chunk.id] = chunk
for rank, chunk in enumerate(keyword_results):
scores[chunk.id] = scores.get(chunk.id, 0) + 1 / (k + rank + 1)
doc_map[chunk.id] = chunk
sorted_ids = sorted(scores.keys(), key=lambda id: scores[id], reverse=True)
return [doc_map[id] for id in sorted_ids]
Query Rewriting for Conversational Inputs
User queries are rarely well-formed retrieval queries. In a conversational interface, follow-up questions contain pronouns and implicit references that only make sense in context. A query like "What does it say about parental leave?" cannot be embedded meaningfully without resolving "it."
A lightweight query rewriting step — a separate, fast LLM call before retrieval — rewrites the user's message into a self-contained retrieval query, substituting context from conversation history.
Cross-Encoder Reranking
After hybrid retrieval returns twenty candidates, a cross-encoder reranker re-scores each chunk independently against the full query. Cross-encoders take the (query, document) pair as joint input — unlike bi-encoders, which embed each independently — and produce calibrated relevance scores. Keep the top 5–8 after reranking, and set a hard relevance threshold below which no chunk passes to the model context.
A context window over 8K tokens consistently degrades generation quality even for models with 128K+ context windows. Precision at the reranking stage is more valuable than recall at the retrieval stage.
Hypothetical Document Embeddings for Sparse Queries
For domains where user queries are exploratory or where the document vocabulary diverges significantly from query vocabulary, Hypothetical Document Embeddings (HyDE) improves recall. The approach: before retrieving, ask the LLM to generate a hypothetical answer to the query, then embed that hypothetical answer rather than the raw query. The hypothetical answer sits closer in embedding space to the actual source documents, improving retrieval for conceptually clear but lexically sparse queries.
Layer 4: Evidence-Grounded Generation
The generation layer's job is to convert retrieved evidence into a trustworthy answer — and to refuse when the evidence is insufficient.
Prompt Design for Grounded Answers
The system prompt must make evidence-grounding a structural requirement, not a soft instruction:
You are a knowledge assistant for [Organization]. Your role is to answer questions based strictly on the retrieved document evidence provided below.
Rules:
1. Answer only what is directly supported by the retrieved evidence.
2. Every factual claim must be followed by a citation in the format [Document Title, Section X].
3. If the evidence does not contain sufficient information to answer the question, respond: "The available documents do not contain enough information to answer this question. [Suggest where to find more information if known]."
4. Do not use prior knowledge to supplement incomplete evidence.
5. If the question asks about something outside the document scope, say so explicitly.
Retrieved Evidence:
{assembled_context}
User Question: {user_query}
Confidence Assessment and Fallback Routing
Not every query should reach the LLM. Define confidence thresholds at the retrieval stage:
- High confidence (top reranker score > 0.85, ≥3 supporting chunks): standard generation path.
- Medium confidence (score 0.60–0.85): generate with explicit uncertainty disclosure in the response.
- Low confidence (score < 0.60): do not generate. Return a structured "insufficient evidence" response and log the query for human review.
- No relevant retrieval: surface this as a knowledge gap, optionally triggering a document request workflow.
Routing to a human reviewer on low confidence is not a failure — it is the correct behavior for a governed system.
Layer 5: Agentic RAG — When Retrieval Becomes Multi-Step
Static RAG — one query, one retrieval pass, one answer — is insufficient for complex enterprise tasks. Agentic RAG introduces planning, iterative retrieval, and tool invocation between query receipt and answer generation.
An agentic pattern for a compliance research task:
User: "Summarize how our GDPR data retention policy compares to the EU AI Act requirements for high-risk systems."
Agent Plan:
Step 1: Retrieve internal GDPR data retention policy documents
Step 2: Retrieve EU AI Act Article 12 and Article 19 provisions (from regulatory index)
Step 3: Identify overlap and gaps across retrieved content
Step 4: Generate comparative summary with citations from both sources
Step 5: Flag any identified compliance gaps for human review
Each retrieval step is independently logged. Each tool invocation is audited. The agent can request a second retrieval pass if its self-evaluation step determines the first pass was insufficient.
Under the EU AI Act's requirements for high-risk AI systems — effective August 2026 — agentic systems deployed in regulated contexts must support interruption of operation (Article 14) and automatic event logging (Article 12). These are architectural requirements, not policy commitments. The system must be technically capable of human interruption at any step, and every agent action must be written to an immutable audit log.
Layer 6: Evaluation as a Production System
Evaluation is not a launch activity. It is a continuous production concern. A RAG system that is not being evaluated is drifting in an unknown direction.
RAGAS Metrics
RAGAS (Retrieval-Augmented Generation Assessment) provides four production-relevant metrics:
| Metric | What It Measures | Acceptable Floor | |---|---|---| | Faithfulness | Are all claims in the answer supported by retrieved context? | > 0.85 | | Answer Relevancy | Does the answer address what the user actually asked? | > 0.80 | | Context Precision | Of the retrieved chunks, how many were actually used? | > 0.70 | | Context Recall | Were the relevant source chunks retrieved at all? | > 0.75 |
Run RAGAS against a human-curated golden dataset of question-answer-source triples. Regression in any metric after an ingestion or retrieval change should block deployment.
Online Feedback Integration
User feedback — thumbs up/down, explicit corrections, escalation events — is production signal that synthetic evaluation cannot replicate. Store it with full context: the query, the retrieved chunks, the generated answer, the user's role, and the timestamp. Feed this into weekly retrieval quality reviews and use it to curate additional golden set examples.
Drift Detection
Document corpora change. Policies are updated. New documents arrive. Outdated content is retired. A retrieval system that was well-calibrated at launch degrades as its index drifts from the live document state. Monitor:
- Index freshness: what percentage of source documents have been re-ingested within their declared refresh interval?
- Retrieval null rate: what percentage of queries return zero relevant chunks above threshold?
- Hallucination rate: track faithfulness score over time; sustained decline signals corpus drift or prompt regression.
Compliance Architecture for Regulated Deployments
Enterprises in regulated industries — financial services, healthcare, legal, public sector — face overlapping obligations that RAG architecture must satisfy structurally:
EU AI Act (August 2026 for high-risk systems):
- Article 12: Technical capability for automatic logging of events during system operation. Minimum six-month log retention.
- Article 14: Human oversight capability including ability to interrupt operation at any point.
- Article 9: Risk management system documented and maintained throughout lifecycle.
GDPR:
- Personal data must not enter retrieval indexes without lawful basis. PII detection at ingestion is mandatory, not optional.
- Data subject access requests must be answerable: which chunks contain data attributable to the requesting individual?
- Right to erasure requires the ability to remove a document and all its derived chunks from the index without full reindexing.
Practical Implementation:
- Log every query, retrieval result, and generated response to an append-only audit store with cryptographic integrity verification.
- Implement document-level deletion capability in your vector database configuration before you need it.
- Run PII detection (presidio, AWS Comprehend, or equivalent) as a mandatory ingestion gate — not a post-processing step.
- Maintain a model registry that records which embedding model, which LLM version, and which prompt template produced every logged response.
Deployment Topology by Sensitivity
Not all enterprise data warrants the same deployment architecture. Tiering workloads by sensitivity reduces cost without compromising governance:
| Tier | Data Classification | Deployment | Model Options |
|---|---|---|---|
| Public | Marketing, public documentation | Cloud API | Any commercial model |
| Internal | General business knowledge, non-personal | VPC-isolated cloud | Commercial model with data processing agreement |
| Confidential | Personnel, financial, client data | Private cloud / on-premise | Open-weight models (Llama 3, Mistral) via local inference |
| Restricted | Regulated data, M&A, legal privilege | Air-gapped infrastructure | On-premise models with no external network access |
The model gateway layer makes tier routing invisible to the user. The same interface routes to different inference endpoints based on the classification of the retrieved documents, not the user's request.
A Staged Implementation Roadmap
Phase 1 — Foundation (4–6 weeks): Deploy hybrid search over a single controlled document corpus. Implement metadata-enforced access control, prompt guardrails, citation generation, and audit logging. Establish a RAGAS golden dataset with fifty curated question-answer-source triples. Do not expand scope until retrieval quality meets defined thresholds.
Phase 2 — Production Hardening (4–6 weeks): Add cross-encoder reranking. Implement query rewriting for conversational context. Build confidence thresholds and fallback routing. Deploy online feedback capture. Integrate PII detection into the ingestion pipeline. Add document expiry management.
Phase 3 — Agentic Extension (6–8 weeks): Introduce multi-step retrieval for complex queries. Add tool invocation (calculators, API lookups, database queries). Implement human-in-the-loop checkpoints for low-confidence agentic steps. Expand the golden dataset to cover multi-hop question types.
Phase 4 — Governance and Scale (ongoing): Automate RAGAS evaluation in the deployment pipeline. Build drift detection dashboards. Implement model registry and version tracking. Conduct quarterly adversarial red-teaming of retrieval boundaries and access controls.
The Decision That Defines Whether This Succeeds
Most enterprise RAG projects are governed by the wrong question. Teams ask: "How do we make the answers better?" The right question is: "How do we make the system trustworthy enough that the organization can act on its answers?"
Trustworthiness is an architectural property, not a quality of the generated text. It comes from knowing what was retrieved, knowing who was authorized to see it, knowing what the model did with it, and having a documented record of every step. It comes from evaluation frameworks that catch regression before users encounter it. It comes from governance boundaries that make unauthorized access structurally impossible rather than policy-prohibited.
A private RAG system built to these standards is not a chatbot. It is a knowledge infrastructure layer — as critical to operate correctly as the document management system it sits in front of.
Build it that way from the start.
Questions about implementing any layer of this architecture? We work with enterprise teams to design and deploy production RAG systems that meet regulatory requirements and deliver measurable knowledge retrieval quality.